Auto ML and AI Module Guide
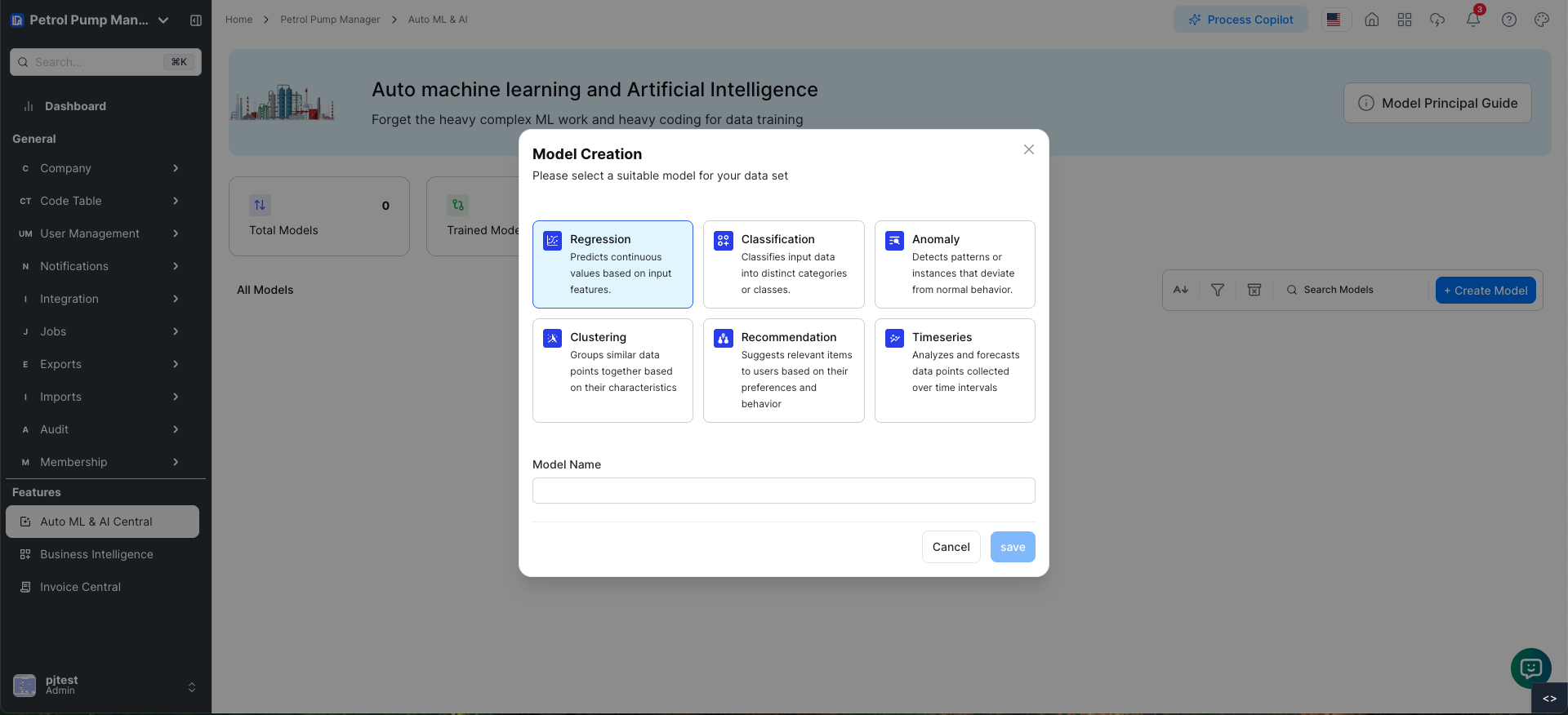
Types of Models in AutoML
Before starting with the Auto ML and AI module, it's important to understand the different types of models that can be trained:
- Regression: Predicts continuous values based on input features (e.g., predicting the price of a house based on its features).
- Classification: Classifies input data into distinct categories or classes (e.g., classifying emails as spam or not).
- Anomaly Detection: Detects patterns or instances that deviate from normal behavior (e.g., fraud detection in financial transactions).
- Clustering: Groups similar data points together based on their characteristics (e.g., customer segmentation).
- Recommendation: Suggests relevant items to users based on their preferences and behavior (e.g., product recommendations on an e-commerce site).
- Time Series: Analyzes and forecasts data points collected over time intervals (e.g., predicting stock prices or weather forecasts).
Step 1: Import Data
Upload Dataset from CSV File
To begin using the Auto ML and AI module, you need to import your dataset. You can upload datasets from a CSV file or from any table within your system.
- Navigate to the "Import Data" page.
- Click the "Upload Dataset" button.
- Select the CSV file you want to upload, such as
titanic_data.csv.
If the file is valid, you will see a confirmation message.
If the file is invalid, you will see an error message prompting you to upload a valid CSV file.
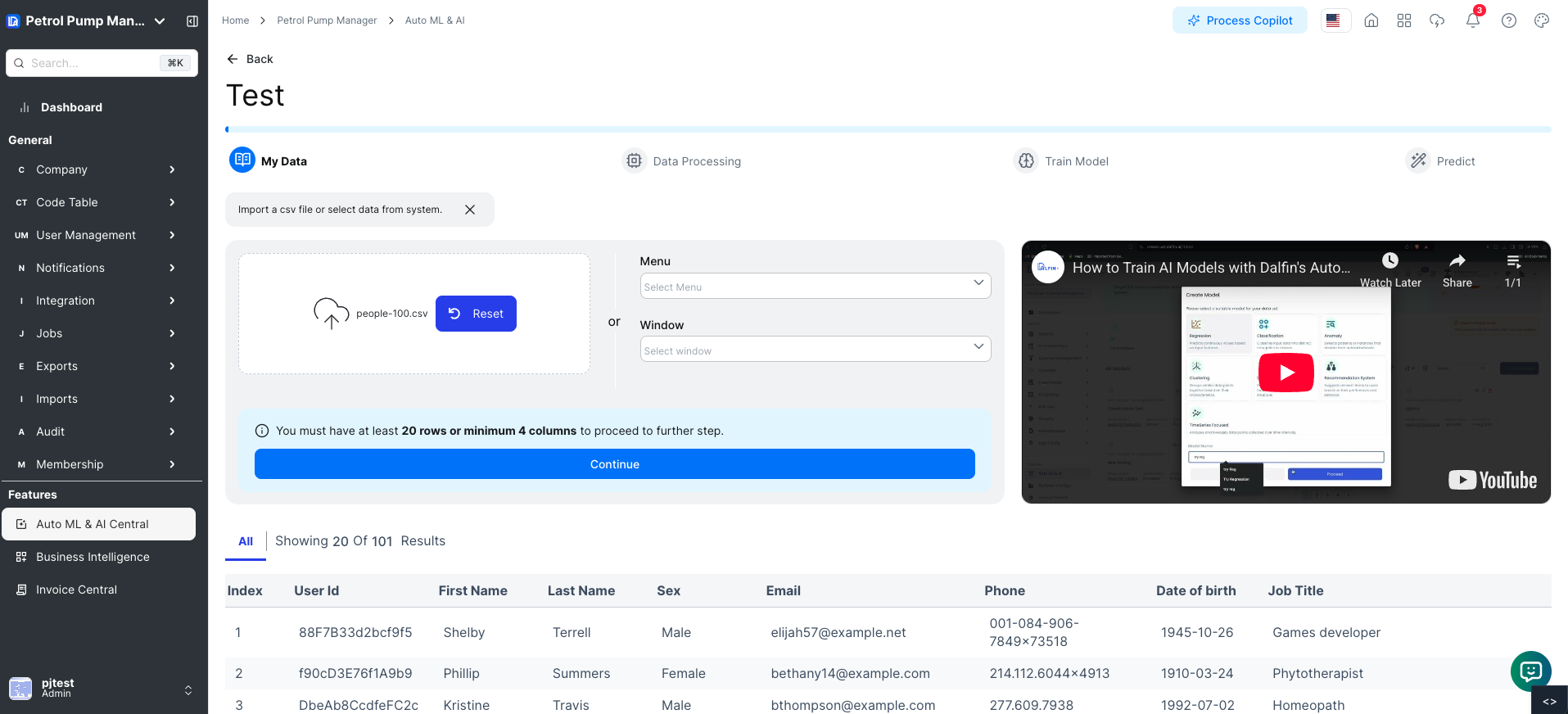
Step 2: My Data
Viewing Uploaded Dataset
Once you have successfully uploaded your dataset, you can view an overview of the data and inspect it in detail.
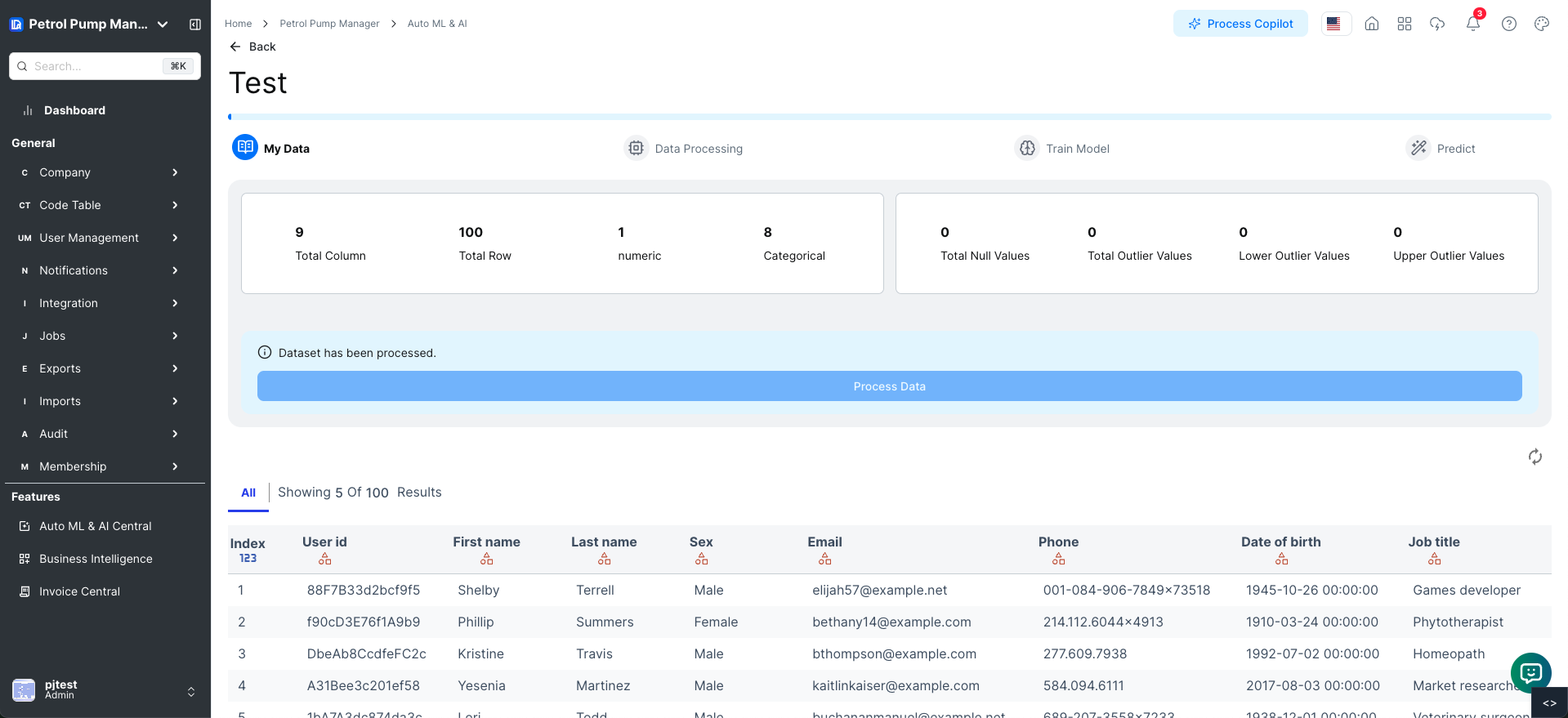
Overview of Uploaded Dataset
- Navigate to the "Uploaded Dataset Overview" page.
- You will see an overview with the following information:
- Total Columns: 12
- Total Rows: 98
- Numeric Columns: 8
- Categorical Columns: 4
- Total Null Values: 92
- Total Outlier Values: 20
- Lower Outlier Values: 0
- Upper Outlier Values: 20
Viewing Dataset in Table Format
- On the "Uploaded Dataset Overview" page, you will also see the dataset displayed in a table format.
- The table includes columns such as
Passengerid,Survived,Pclass,Name,Sex,Age,Sibsp,Parch,Ticket,Fare,Cabin, andEmbarked. - By default, the first 5 rows of the dataset are displayed.
Searching Within the Dataset
Use the search bar on the "Uploaded Dataset Overview" page to search for specific entries, such as "James".
Pagination in Dataset Table
Use the pagination controls to navigate through the dataset. For instance, go to page 2 to see rows 6 to 10 of the dataset.
Handling Invalid CSV File Uploads
If you upload an invalid CSV file, such as invalid_data.csv, the system will display an error message indicating the file is invalid.
Step 3: Data Processing
Data Processing
- On the "Data Overview" page, click the "Process Data" button.
- The system will:
- Clean the data
- Normalize the data
- Handle missing values
- The processed data will be displayed in a table view.
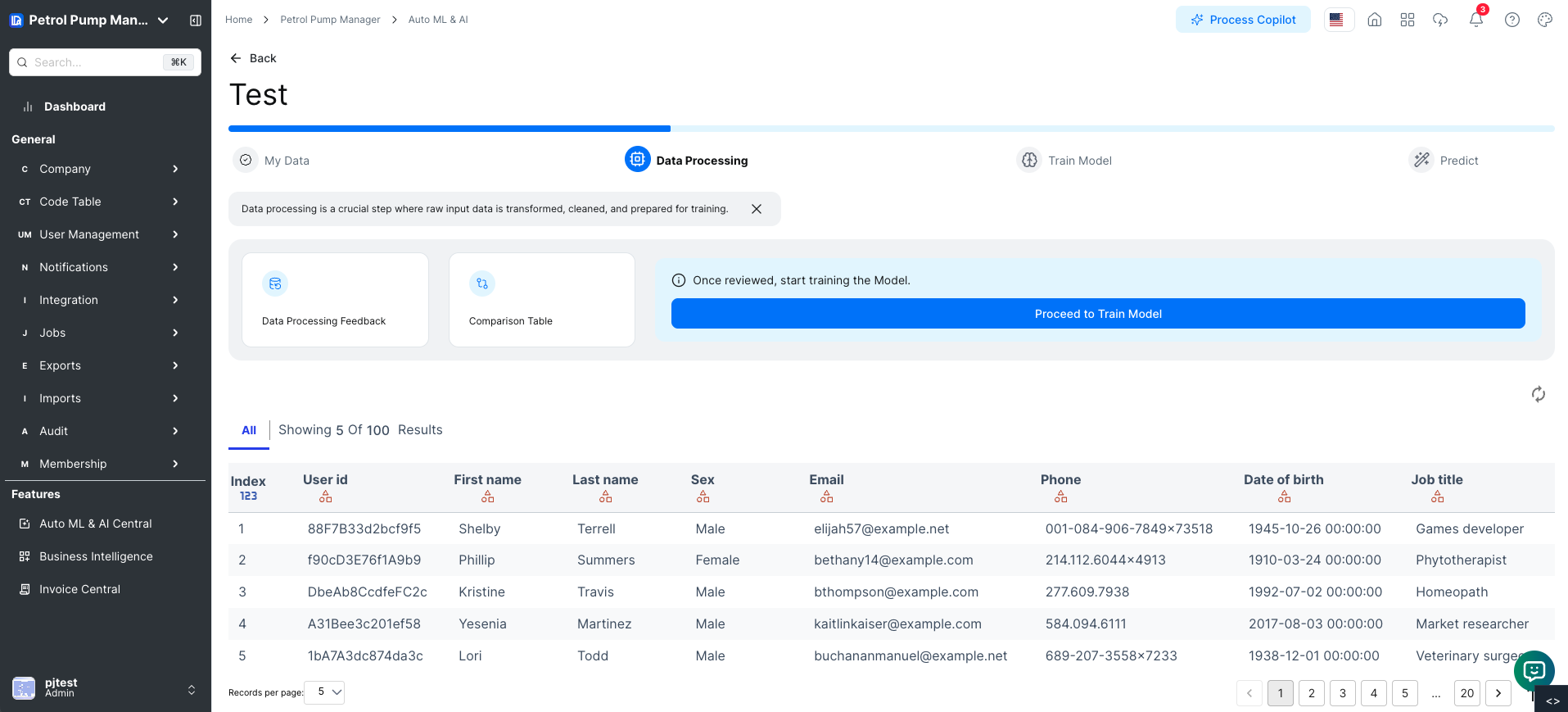
You will also see options to visualize the data through scatter plots, correlation matrices, and distribution plots.
Visualizing Data
- After processing the data, navigate to the "Data Visualization" page.
- You can view various visualizations, such as:
- Scatter plots
- Correlation matrices
- Distribution plots
- Customize the visualizations by selecting X-axis and Y-axis for scatter plots and selecting columns for the correlation matrix.
Step 4: Train Model
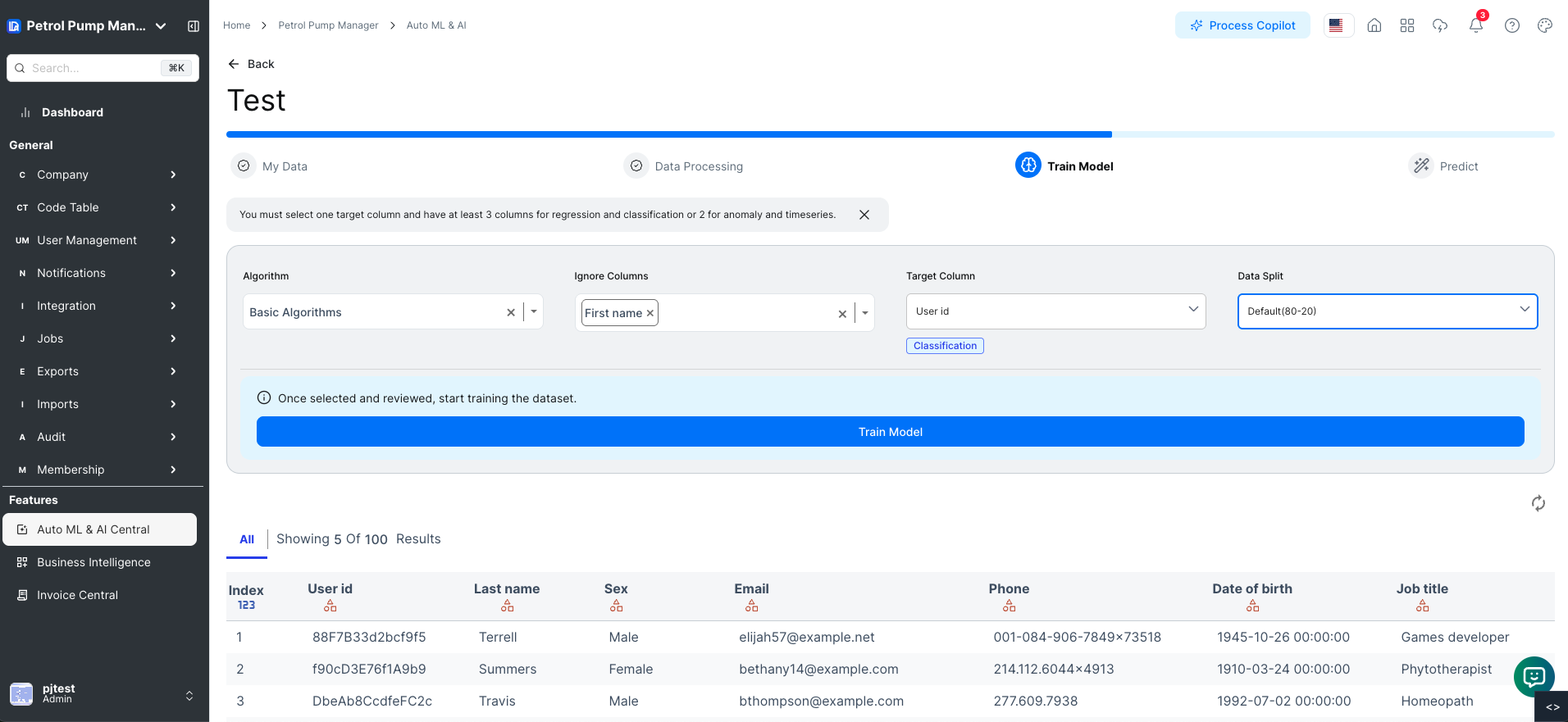
Configuring Training Data
- Navigate to the "Configure Training Data" page.
- You will see a list of all columns in the dataset.
- Select the columns to ignore, such as
Name,Ticket, andCabin. - Click the "Ignore Selected Columns" button to remove the selected columns from the dataset.
- Select
Survivedas the target column. It will be marked as the target variable. - Set the data split to 80% for training and 20% for testing.
- Click the "Apply Split" button to divide the dataset accordingly.
- Review the configured dataset to ensure it is correctly updated, with ignored columns removed, the target column marked, and data split into training and testing sets.
Viewing and Selecting the Best Model
- As an authorized user, view the models available in table
Titanic Data. - Each model will display metrics such as
accuracy,precision score,recall score, andF1 score. - Select the model with the highest performance metrics.
- Use the selected model to perform predictions.
By default, the highest performance model will be selected. But there is also the option to select other models manually.
This guide provides an overview of the steps involved in importing data, processing it, and training models using the Auto ML and AI module. For detailed instructions, follow each section accordingly.